«I changed by not changing at all», cantaba Eddie Vedder en una de las canciones acústicas más hermosas que se hayan escrito. Esa frase resume por qué encallan la mayoría de reorganizaciones corporativas: las empresas deciden cambiar algo basándose en subjetividad y sesgos, en lugar de aplicar un sistema racional que optimice la decisión.
Vamos a hablar de toma de decisiones multicriterio, aplicada a un caso concreto: reorientar una estructura de equipos hacia dominios de negocio.
De reorganización de equipos de software
“¿Cómo que la frontera de trabajo entre los equipos no está clara?” A mí, germanófilo empedernido, me gusta mucho responder con un jein (esa mezcla alemana de ja y nein, sí y no).
El tiempo pasa y tu producto evoluciona. Tus equipos se van desalineando del negocio por pura inercia del mercado y tu producto. Un día el desajuste es tal que alguien aparece con la idea feliz de reorganizar la casa. Y no es infrecuente que se proponga con cierta resignación. Vamos, que ese alguien preferiría, en el fondo, no tener que tocar nada.
Decisiones multicriterio en la vida real: produciendo software
La siguiente parte de esta nota es una descripción de pequeño framework para ayudar a valorar las alternativas de forma más o menos objetiva. Vamos con un ejemplo paso a paso.
1. Entender las alternativas
¿Qué opciones tenemos realmente?
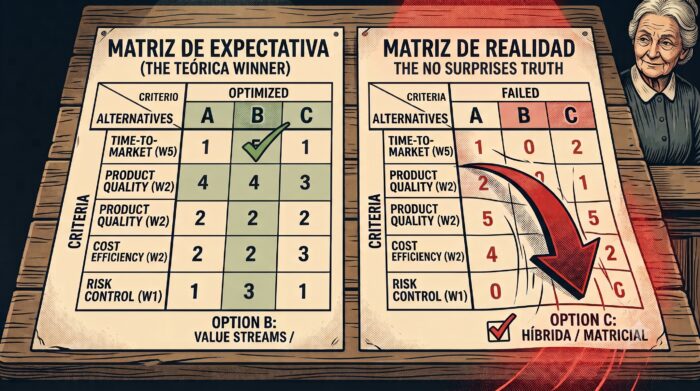
- A: Silos Funcionales. Cada departamento a lo suyo, paso de testigos (handoffs) y asignación de recursos por proyecto.
- B: Orientación a Negocio / Value Streams. Equipos multidisciplinares, estables y autónomos, enfocados a un producto o flujo de valor.
- C: Estructura Híbrida / Matricial. Equipos de proyecto temporales, con personas que siguen reportando a sus jefes funcionales.
En no pocos casos la opción A es el statu quo, la B es la que se declara en el PowerPoint, y la C es la que se acaba adoptando porque permite salvar la cara a (casi) todos los stakeholders, aunque deje sin tocar problemas de fondo.
2. Acordar criterios ponderados
En un escenario real descubrir estos criterios llevará un buen rato, idealmente de trabajo en equipo. Por no complicarnos, trabajemos con cuatro criterios sencillos:
| Criterio | Peso |
| Time-to-Market / Foco en Negocio: «Queremos entregar valor rápido» | 5 |
| Calidad del Producto «Cero bugs en producción» | 2 |
| Eficiencia de Costes «Optimizar el presupuesto» | 2 |
| Control de Riesgos «Seguridad y procesos robustos» | 1 |
Lo siguiente es ver qué puntuación merecen cada una de las alternativas en cada uno de estos ejes, ponderamos el resultado por el peso del mismo, y vemos cuál es la opción que sale triunfadora en base a este marco.
¿Qué cabe esperar? En muchos casos, puede que el resultado diga una cosa pero la realidad observada diga otra.
Aquí está la pregunta que estábamos esperando: si la matriz dice que B es la ganadora absoluta, ¿por qué seguimos operando en A o atascados en C?
Lo has vivido. Todos lo hemos vivido. Según McKinsey, cerca del 90% de las organizaciones experimenta con cambios estructurales o tecnológicos, pero apenas un 7% logra un despliegue con impacto real.
La disonancia cognitiva entre resolverlo en la pizarra e integrarlo en la cultura del día a día es salvaje. Cantaba Sabina “que no hay ser humano que le eche una mano a quien no se quiere dejar ayudar”. Ningún workshop puede arreglar un sistema que, en el fondo, no quiere ser arreglado.
La abstracción metodológica como eliminador de fricción
La genialidad de este marco reside en confrontar al grupo con tres verdades de forma que sean difíciles de soslayar:
- Externaliza el pensamiento: Baja el debate de la cabeza (donde sesgos, política de pasillo y emociones distorsionan la realidad) a un plano lógico. Esto va de datos. No es nada personal.
- Obliga a consensuar los criterios: El conflicto de base es que cada stakeholder tiene intereses distintos y prioriza cosas distintas. Acordar criterios y ponderarlos ayuda a alinear la importancia relativa de los diferentes factores.
- Evita el autoengaño: Si la matriz dice una cosa pero pero la organización sigue queriendo hacer otra, aquí hay tomate. Hay criterios que no se pusieron sobre la mesa pero siguen pesando en la decisión final.
Y ahí empieza la diversión.
Haciendo aflorar los Criterios Ocultos
La hora de la verdad.
En un proceso puramente racional, la organización acordaría el plan para migrar a la opción que sumó más puntos y todos tan contentos. Pero, para sorpresa de nadie, eso no suele suceder..
Cuando las matemáticas dan una opción ganadora pero el cambio no llega y al final se paraliza, es porque se están ponderando criterios que nadie ha querido poner sobre la mesa. Javier Recuenco, acostumbrado a lidiar y evangelizar sobre la resolución de problemas de esta índole, diría que tu subconsciente ya había decidido comprar salmón y toda la conversación posterior sobre nutrición te sobraba bastante: ni dieta equilibrada, ni variedad, ni leches. SAL-MÓN. Es a lo que habías venido y es lo que vas a comprar. Y los números, que esperen.
Pero te estás haciendo trampas al solitario. Y lo sabes.
El verdadero valor de usar un framework de decisión multicriterio como el del ejemplo no es sacar una nota media intentando encontrar una solución que permita nadar y guardar la ropa, sino obligarte a un ejercicio de honestidad sacando a la luz los criterios implícitos que están condicionando la decisión pero de los que no se está hablando.
Algunos ejemplos:
- Pérdida de control e influencia: Tras una reorganización hacia dominios de negocio, los jefes de áreas funcionales tienen un rol diferente. ¿Cuánto miedo hay a perder el feudo?
- Garantía de utilización de recursos: El pánico funcional a que un programador esté “parado” un día porque el equipo de producto no lo necesita en ese sprint. Se sigue priorizando la eficiencia de recursos sobre la eficiencia de flujo (que por cierto es algo que impacta sobre el time-to-market, que era un criterio en la matriz que usamos más arriba), sobre esto hablé en su día cuando tratamos eficacia vs eficiencia.
- Sensación de seguridad personal: En la estructura funcional, con múltiples áreas implicadas, la responsabilidad sobre un fracaso se diluye. En un equipo de producto, la responsabilidad es compartida e ineludible. El silo provee ciertos escondites y una dosis de paz mental.
- Sobrecarga cognitiva de gestión: Cambiar a negocio implica cambiar gobernanza y habilitar nuevas líneas de comunicación, sacar a muchas personas de su zona de confort para que traten con personas con las que antes no necesitaban tratar.

El fin de la mascarada y el diseño correcto de incentivos
Poner sobre el papel tanto la conducta declarada como la naturaleza subyacente de la organización produce un efecto definitivo: presenta un autorretrato imposible de ignorar. Es el fin del cinismo. Ya nadie puede sostener que la empresa prefiere el time-to-market cuando es obvio que pondera el control.
Lo que la organización elige de verdad, no lo que dice elegir, está perfectamente calibrado para lo que a al management de la misma le importa.
Llegados a este punto, la misión es rediseñar los objetivos y mover la discusión al sitio correcto. El debate ya no puede seguir siendo metodológico; ahí ya no queda nada por discutir. Toca hablar de lo político y lo cultural.
Quizá sea más relevante repensar el variable a corto plazo (el famoso bonus) de esos managers para que cobrarlo dependa de tomar la decisión estructural correcta. O trabajar explícitamente en cómo gestionar el miedo al error si eliminamos los silos que les sirven de refugio, construyendo una cultura corporativa que premie de verdad el experimentar y aprender rápido.
Al final, como en aquella mujer de la canción de Pearl Jam que vio pasar la vida desde detrás de un mostrador, el mayor riesgo de las empresas es ver pasar los años cambiando cosas de sitio para seguir, en el fondo, exactamente en el mismo lugar.
[Imagenes. Jose Alcántara con Gemini.]